文章图片
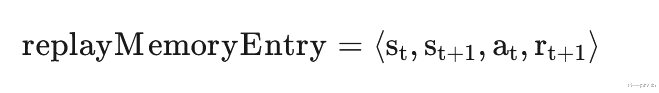
文章图片

文章图片
这是一个我已经断断续续地研究了很长一段时间的项目 。 在此项目之前我从未尝试过修改游戏 , 也从未成功训练过“真正的”强化学习代理(智能体) 。 所以这个项目挑战是:解决钓鱼这个问题的“状态空间”是什么 。 当使用一些简单的 RL 框架进行编码时 , 框架本身可以为我们提供代理、环境和奖励 , 我们不必考虑问题的建模部分 。 但是在游戏中 , 必须考虑模型将读取每一帧的状态以及模型将提供给游戏的输入 , 然后相应地收集合适的奖励 , 此外还必须确保模型在游戏中具有正确的视角(它只能看到玩家看到的东西) , 否则它可能只是学会利用错误或者根本不收敛 。
我的目标是编写一个能读取钓鱼小游戏状态并完美玩游戏的代理 。 目标的结果是使用官方 Stardew Valley 的 modding API 用 C# 编写一个自动钓鱼的mod 。 该模块加载了一个用 Python 训练的序列化 DQN 模型 。 所以首先要从游戏中收集数据 , 然后用这些数据用 Pytorch 训练一个简单的 DQN 。 经过一些迭代后 , 可以使用 ONNX 生成一个序列化模型 , 然后从 C# 端加载模型 , 并在每一帧中接收钓鱼小游戏的状态作为输入 , 并(希望)在每一帧上输出正确的动作 。
钓鱼迷你游戏这个代理是在SMAPI的帮助下编写的 , SMAPI是Stardew Valley官方的mod API 。 API允许我在运行时访问游戏内存 , 并提供我所需要的一切去创造一个与游戏状态进行交互并实时向游戏提供输入的代理 。
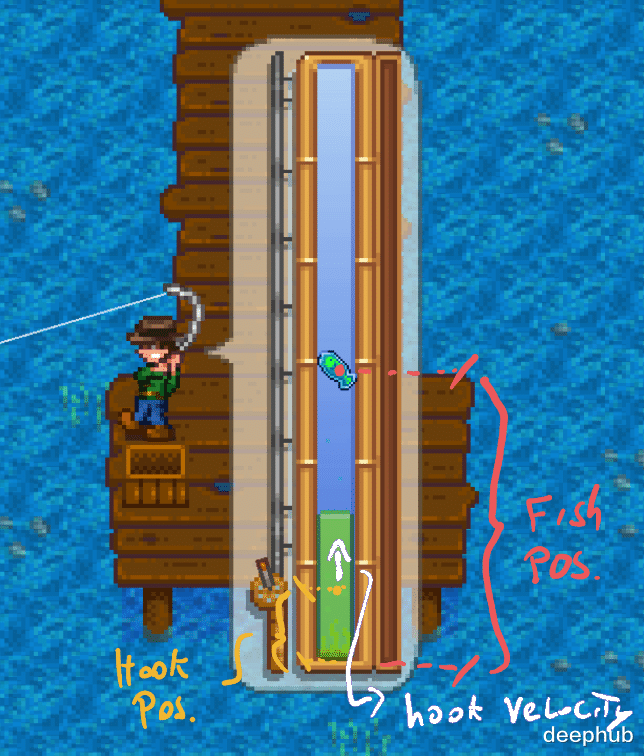
在钓鱼小游戏中 , 我们必须通过点击鼠标左键让“鱼钩”(一个绿色条)与移动的鱼对齐 。 鱼在这条竖线上无规律地移动 , 鱼钩条与鱼对齐时 , 绿色条就会填满一些 , 如果鱼成功逃离绿色条就会开始变空 。 当你填满绿色的条形图时 , 你会钓到鱼 , 当它绿条没有时鱼就跑了 。
强化学习问题定义
所以这里只需要每帧从游戏内存中读取这些特定属性并将它们保存为在第 t 帧的状态 。 通过API我们可以查看并从游戏内存中读取特定属性的代码 , 对于自动钓鱼 , 需要在钓鱼小游戏期间跟踪的 4 个变量 。“钩子”中心的位置、鱼的位置、钩子的速度和绿色条的填充量(这是奖励!) 。游戏内部使用的名称有点奇怪 , 以下是读取它们的代码 。
/ Update State
// hook position
bobberBarPos = Helper.Reflection.GetField<float>(bar \"bobberBarPos\").GetValue();
// fish position
bobberPosition = Helper.Reflection.GetField<float>(bar \"bobberPosition\").GetValue();
// hook speed
bobberBarSpeed = Helper.Reflection.GetField<float>(bar \"bobberBarSpeed\").GetValue();
// amount of green bar filled
distanceFromCatching = Helper.Reflection.GetField<float>(bar \"distanceFromCatching\").GetValue();
前三个定义了我们的状态:
这是模型可以在每一帧上可以获取的状态 , 要将其设置为强化学习问题还需要使用奖励来指导训练 。奖励将是绿色条的填充量 , 这是里的变量名称为 distanceFromCatching 。这个值的范围从 0 到 1 , 正好非常适合作为奖励 。
Replay MemoryReplay Memory是 Q-learning 中使用的一种技术 , 用于将训练与特定的“时间”去关联 。所以需要将状态转换存储在缓存中并通过缓存中随机抽取批次来训练模型而不是直接使用最新数据进行训练 。为了训练模型 , 我们需要 4 个数据 , 分别是当前状态、下一个状态、采取的行动和奖励:
- 观众|双鸭山市首次通过云上直播迎新春音乐会
- 招聘|这一“国企”招聘不限学历,面试通过就可以上岗,专科生机会更大
- |80后手艺人用2022根树枝做冬奥会雕塑:通过自己的手艺为冬奥会加油
- 冰墩墩$80后手艺人用2022根树枝做冬奥会雕塑:通过自己的手艺为冬奥会加油
- |长城币2角硬币,流通过的收藏价值300元左右,你能找到吗?
- 论述|陕西“非物质文化遗产”全国征文大赛第四十九赛区第(1)批征稿初审通过名单
- 翡翠|翡翠原石如何通过皮壳判断赌石种老和种嫩
- 童子$太上老君与菩提祖师的差距,已经通过徒弟之间的对比显现了出来
- 招商证券|如何提升面试通过率?教你一招,面试前把这些功课做好
- 高宗&清代用儒家道统强化统治合法性,以祀孔尊儒来贯穿知识分子的思想